CKAN Instance Analysis
Introduction
This blog post documents the process of gaining insight into the CKAN ecosystem through the analysis of CKAN instances. Using datashades.info and dataportals.org as starting points for portal discovery, portal URLs were compiled and tested for functionality before analyzing properties related to their size, location, and age. In all, 381 of the URLs compiled provided a response to at least one test that was consistent with that of a functioning CKAN instance. Portals were found in 59 countries; they range in size from 0 to 1,000,000+ datasets; and they are generally maintained regularly after being launched.
This analysis was conducted as part of the ecosystem discovery efforts funded through the U.S. National Science Foundation’s Pathways to Enable Open Source Ecosystems (POSE) program. A team from the University of Pittsburgh and datHere are collaborating to develop a plan to strengthen the CKAN ecosystem.
Discovery
One of the initial challenges in attempting to understand the CKAN ecosystem is finding examples of CKAN instances online. As it stands, there is no single, comprehensive list of existing or historic CKAN instances. CKAN’s homepage, ckan.org, lists a few of the more prominent entities that use CKAN (such as the Government of Canada and the U.S. government’s data.gov open data website), but it does not provide additional info on the subject beyond the names of these select few users.
That said, there are two websites that have tried to compile lists of CKAN instances: datashades.info (“Datashades”) and dataportals.org (“Dataportals”). Datashades was launched by Link Digital in the fall of 2019. The site “provides a publicly-accessible index of metadata and statistics on CKAN data portals across [the] globe” through the use of a crowdsourced indexing scheme. Datashades seems to be the most-comprehensive resource online dedicated to exclusively documenting CKAN portals. Dataportals was launched in the summer of 2011 by the Open Knowledge Foundation, and we were able to use the catalog to identify additional data portals to include in our list.
Compiling CKAN portals into one list is the first step in learning more about who relies on CKAN to publish their data, where they are located, and how active they are in using CKAN.
Preprocessing
Before any analysis could be performed on the portals listed on these two sites, we needed to confirm that the portals are 1) instances of CKAN, and 2) still valid. A list hosted at datashades.info/portals contains the URLs for 528 portals, and a CSV download link on Dataportals’ landing page contained information on 591 data portals. These two lists were scanned and cross-referenced to eliminate duplicates, and GET requests were sent to each unique site. GET requests are a method to check the status and content of a website. For these preprocessing purposes, the GET requests were intended to be a way of quickly going through the list of URLs and asking, “Does this website work?”.
Of the 516 unique URLs from Datashades, 469 (91%) returned a 200 status code. The 200 status code means that there is a functioning website at the URL that was tested; however, this status code does not tell us whether the site still hosts a CKAN instance. For example, a website where the owner deleted the CKAN instance but left up text that said, “Have a nice day!” would return a 200 status code. From the 509 URLs from Dataportals that were internally unique and not otherwise found on the Datashades list, 419 (82%) returned a status code of 200. From there, the default URL path for CKAN’s API (“api/3/action/”) was appended to each URL in an attempt to make API calls. This allowed us to make use of some of CKAN’s built-in functions:
- status_show: this function provides basic metadata about the CKAN instance
- package_list: a list of the datasets hosted on the CKAN instance
- organization_list: a list of the different entities that own datasets within the instance
- tag_list: a list of the keywords associated with the datasets
- current_package_list_with_resources: a list of datasets with additional information and metadata about each one
By combining both the datashades and dataportals list, and using the list to make API calls, we were able to identify 376 active CKAN data portals Additionally, we added the URLs of five instances that we found during our ecosystem discovery efforts that were not already on either list, bringing the total to 381.
Note: For the purposes of this analysis, we considered any data portal that had a valid response to at least one API call using CKAN’s functions to be an instance of CKAN. Ideally, an instance would have valid responses to every call made, but because a CKAN user can customize whether or not certain API calls provide responses, we considered even one valid response to be cause for inclusion in further analysis.
Initial Analysis
Using the data gathered from the CKAN API calls, we considered the size and geographic distribution of CKAN instances; we calculated an estimated age/lifespan of each CKAN instance; and we considered elements of the data that would be useful in future analyses.
Instance Size
The sizes of the CKAN instances, measured in number of datasets hosted on the instances, were calculated using the CKAN “package_list” function, an API call that returns a list of every dataset hosted on a CKAN instance. (Note: datasets were called “packages” in early versions of CKAN, and this original name is still used in API calls. “Package” and “Dataset” may be used interchangeably in this post.) Of the 381 instances with valid CKAN API responses, 376 instances had valid responses to the “package_list” API call.
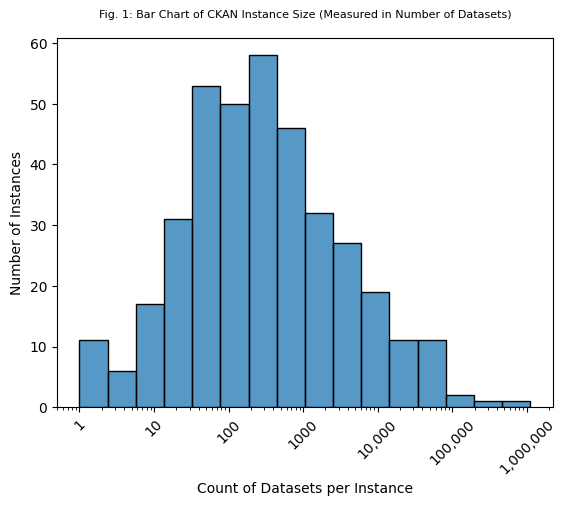
The median number of datasets for the entire group of 376 instances is 242; however, this number is distorted by a handful of instances that host a disproportionately large number of datasets. While 269 of the instances (~72%) host 1000 datasets or fewer, 10 of the instances (~3%) host more than 50,000 datasets. The top 3 CKAN instances are EUDAT B2Find research publication data portal (1.12 million datasets), the Government of Indonesia’s Satu Data Indonesia data portal (255,067 datasets), and the Geological Survey of Queensland Open Data Portal from Australia (175,203 datasets).
Geographic Distribution
A valuable component of understanding the CKAN ecosystem is understanding where CKAN instances are being adopted as the open data platform-of-choice. Unfortunately for our purposes, CKAN’s metadata does not appear to contain a “nationality of origin” tag for the various instances that have been launched. To begin to form an understanding of the geographic distribution of CKAN, the instances’ URLs were used as a proxy for location.
For the purposes of this analysis, CKAN instances were said to be “from” a country if the top-level domain of their URL was associated with a specific country (such as “.mx” and Mexico or “.tn” and Tunisia). If the instance’s URL had a “.com” or “.org” top-level domain, the content of the instance was manually checked quickly to see if its data and/or purpose were associated with a single country. CKAN instances were excluded from this level of analysis if they contained data on multinational regions (e.g. Open Data Africa, Open Development Mekong) or if it contained data on one country or countries that was gathered by a separate country.
Using this method, CKAN instances were found in 59 countries, spread across the six major continents (we have not yet found a CKAN instance running on Antarctica). The median number of instances per country with a CKAN instance was 2, and the mean was 6.1 (with a standard deviation of 10.15). The 10 countries with the most CKAN instances on our list, as well as the number of instances found in each country, are as follows:
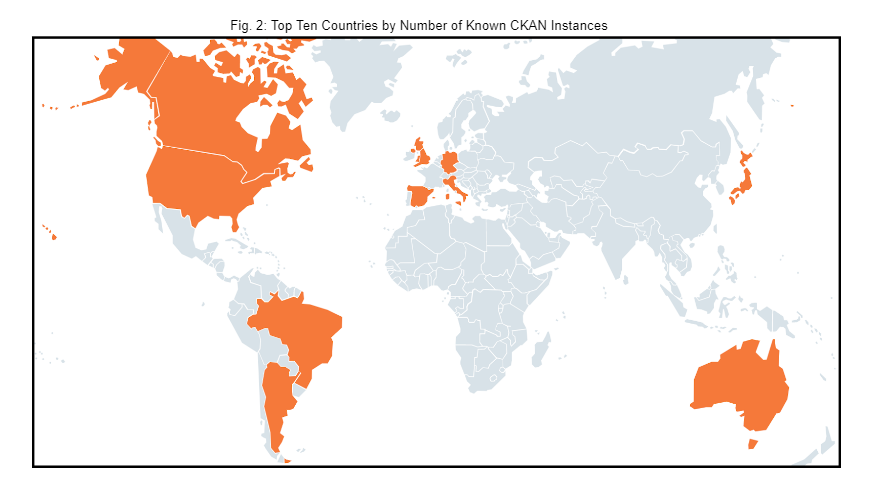
- Brazil (57)
- USA (47)
- Argentina (21)
- Australia (20)
- Canada (20)
- Germany (16)
- UK (16)
- Spain (13)
- Italy (12)
- Japan (10)
Age of CKAN Instances
While the metadata within the CKAN API does not contain a definitive “launch date” for a given instance, there are some pieces of information that can be used as proxies to understand an instance’s age. When using the current_package_list_with_resources function, one piece of information provided is the “metadata creation date” for each dataset on the website. For the purposes of this analysis, the oldest creation date among the dates for all datasets was assumed to be the birthdate of the CKAN instance.
This same function also contains the date that the metadata for each dataset was last edited. This can be used as a proxy to understand how often the instance is still actively used by its creators: if the most recent “last edited” date for any dataset is the same as the earliest “metadata creation date”, it suggests that the datasets were posted and have not been touched since the initial upload. If, however, there is a long span of time between the metadata creation date and the last edited date, it suggests that someone is still maintaining the instance.
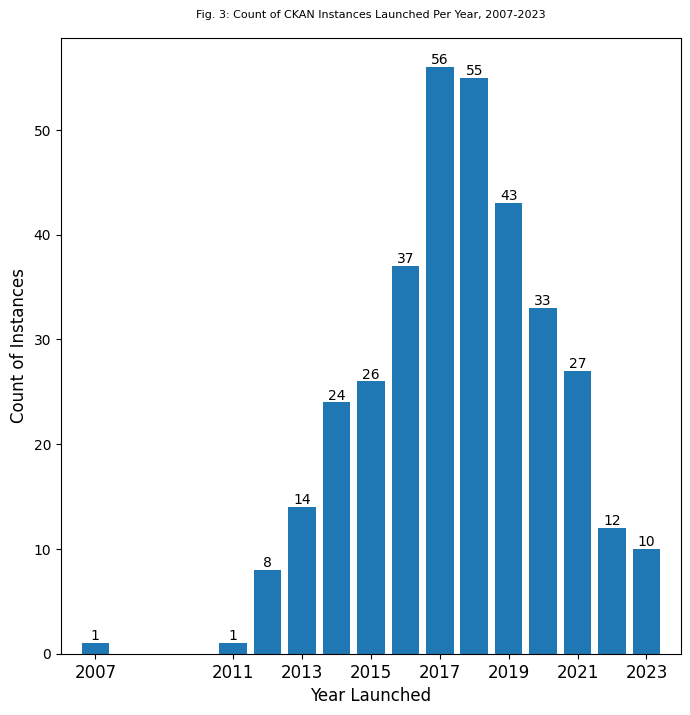
Of the 381 CKAN instances with at least one valid response to an API call, there were 347 that had both a “metadata creation date” and a “last edited” date, and also both of the dates made sense (one CKAN instance removed from this level of analysis, for example, had a “metadata created date” of January 1, 1970). The first CKAN instance was released in 2007, but the second instance found on the list did not appear until 2011. From that point to the present, the number of instances launched by year form a curve that peaks in the year 2017, a year in which 56 CKAN instances were launched.
The metadata dates were also used to calculate a percent of each instance’s “lifespan” that it has been active. For these purposes, the “lifespan” was the number of days between the instance’s “last edited” date and its “metadata creation” date. As a proxy for the percent of an instance’s lifespan that it has been active, the “lifespan” was divided by the difference between today’s date and the earliest “metadata creation” date. In other words:

The denominator represents the full length of time that the instance could have been updated, while the numerator represents the amount of time that the instance has actually been updated. If the instance had been last updated today, the result of this equation would be a 1. If the instance was two years old, but updates had ceased after the first year, the result of the equation would be 0.5. Once the lifespan was calculated for each instance, the lifespans for all instances launched within the same year were averaged.
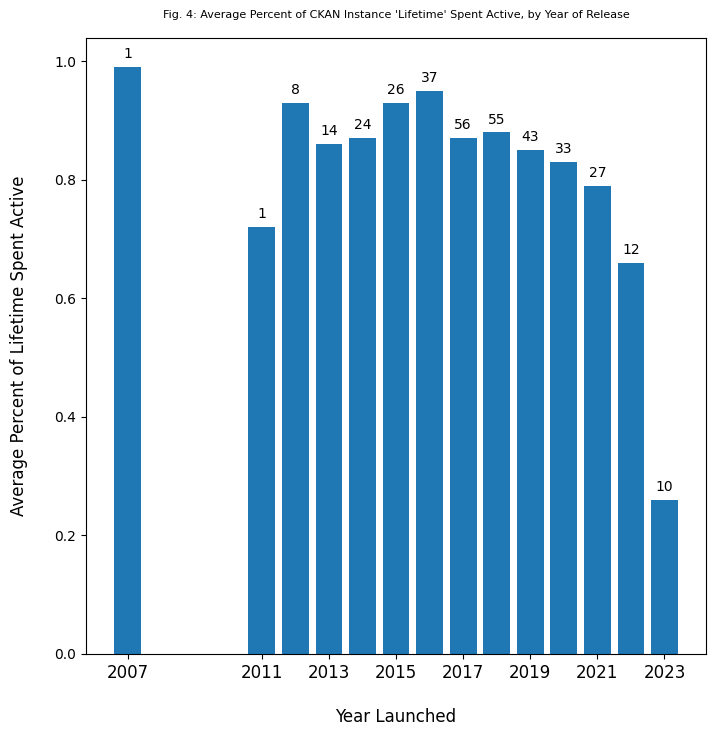
The chart above represents the percent of lifetime spent active for the various CKAN instances. The data is grouped by the year the instances were launched, with the total number of instances per year listed atop each bar. For almost every year, we see that the average “lifespan” is above 80%.
The biggest outliers are 2011, a year for which we only have a record of one instance launching; and 2023, a year for which the instances on record may not have needed an update yet (e.g. if an instance hosts data that updates annually). This all suggests that most users who take the time to set up CKAN instances have some level of commitment to the ongoing use and maintenance of their CKAN instance.
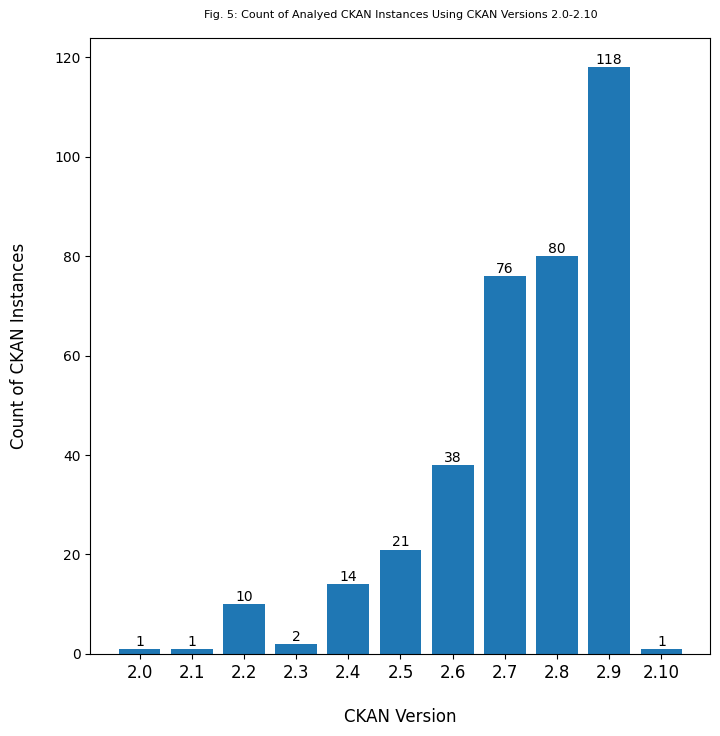
CKAN Version
362 of the instances returned information about the version of CKAN that is currently used by the organization. At the time the API calls were made, only one of these instances had upgraded to the latest version of CKAN (2.10). Nearly a third of the instances are using some version of CKAN 2.9, but roughly a quarter of the instances are still using a version of CKAN that is below CKAN 2.7.
Future Analysis and Actions
The steps described above were only intended to gain a cursory understanding of the CKAN ecosystem, and are by no means the only ones that can be taken. From the data that has already been gathered in these efforts, additional analysis can be performed on aspects of the various instances (such as the number and type of extensions that have been added to an instance by the user). Beyond the previously gathered data, CKAN has more API functions than those described above which, with additional API calls, could result in the collection of data outside of the scope of this blog post.
Additional analysis notwithstanding, the exploration above suggests some themes and trends that can be useful to keep in mind as the POSE project progresses. The number of CKAN instances known to us declines annually after 2018; this decline suggests possible value in continuing to make connections across the community of users (to discover instances and users currently unknown to others in the ecosystem) or to find ways to boost the adoption of CKAN as a data management solution. Furthermore, most CKAN instances are not using the latest version of the product (2.10) suggesting potential value in conducting outreach and providing technical assistance to assist with upgrading to a more secure and sophisticated version of the platform.